
Over the last months I’ve been building a very specific capability into Combotto: a repeatable audit engine that turns real system evidence into a structured report, a prioritized remediation backlog, and a delivery flow you can run again (daily/weekly/release-based) to prevent drift.
Today, that audit engine is ready for pilot projects and internal use.
This matters because IoT systems rarely fail because of one big mistake. They fail because of dozens of small gaps—TLS drift, broker misconfig, weak identity, missing durability signals, observability blind spots—until an outage or customer review makes it visible. A one-off checklist doesn’t hold up over time. Repeatable evidence does.
What’s new (pilot-ready features)
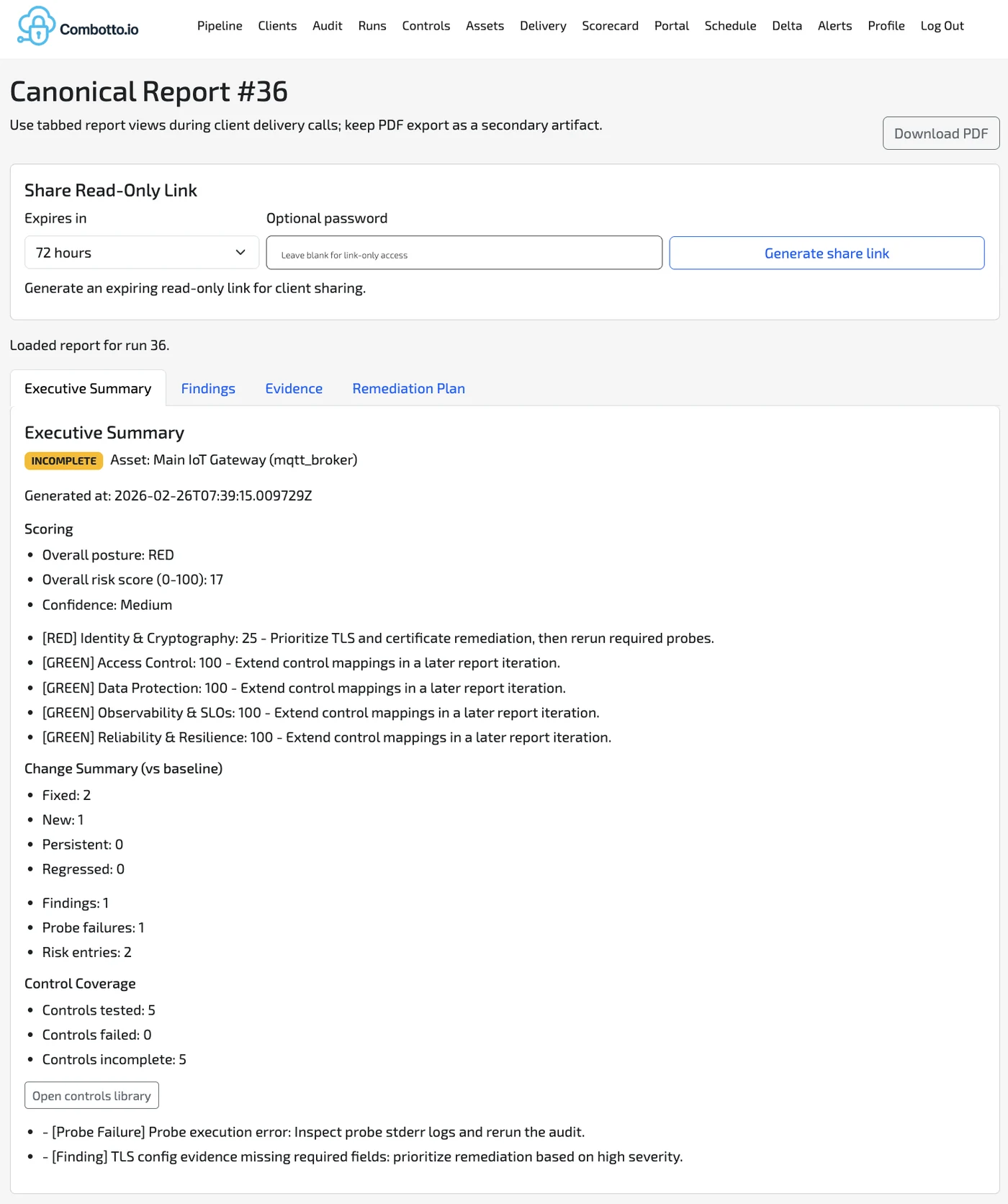
1) Canonical report view (built for delivery calls)
The canonical report is designed to be used live during delivery and remediation planning:
- Executive Summary for leadership-level decisions
- Findings for engineers
- Evidence for verification and traceability
- Remediation Plan for a concrete backlog you can execute
It also supports:
- Shareable read-only links (expiring, optional password) so you can share the report without handing over internal tooling access.
- PDF export as a secondary artifact (good for procurement, security questionnaires, and audit trails).
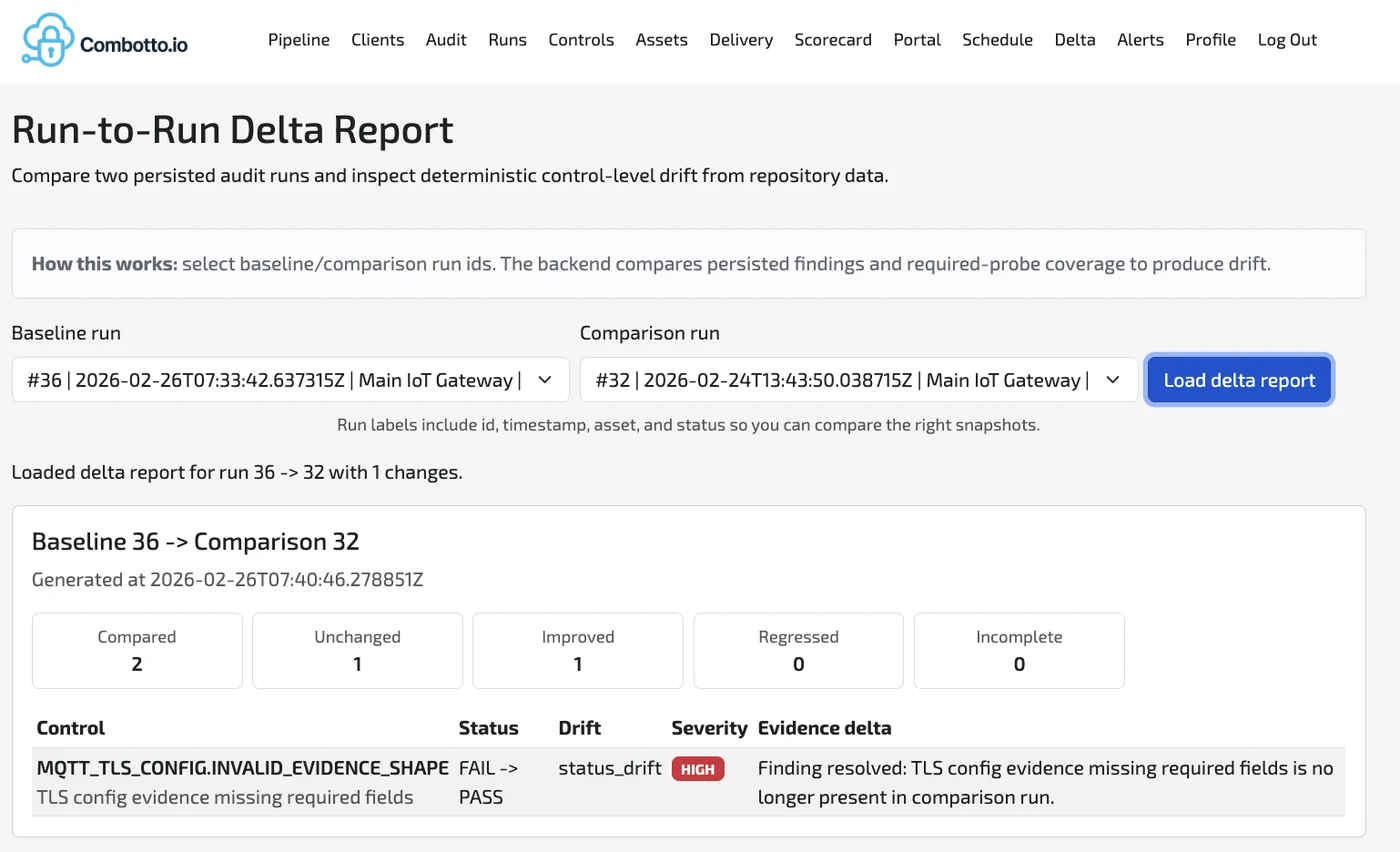
2) Run-to-run delta reporting (drift you can see)
Once you run audits repeatedly, the question changes from “what’s the posture?” to:
What changed since last time—and is it better or worse?
The delta report compares two persisted runs and gives deterministic control-level drift:
- Compared / unchanged / improved / regressed summaries
- Control-level “FAIL → PASS” (or the reverse) transitions
- Severity on drift so you can prioritize quickly
This is the core of a retainer model: you can prove improvement, and you can detect regressions early.
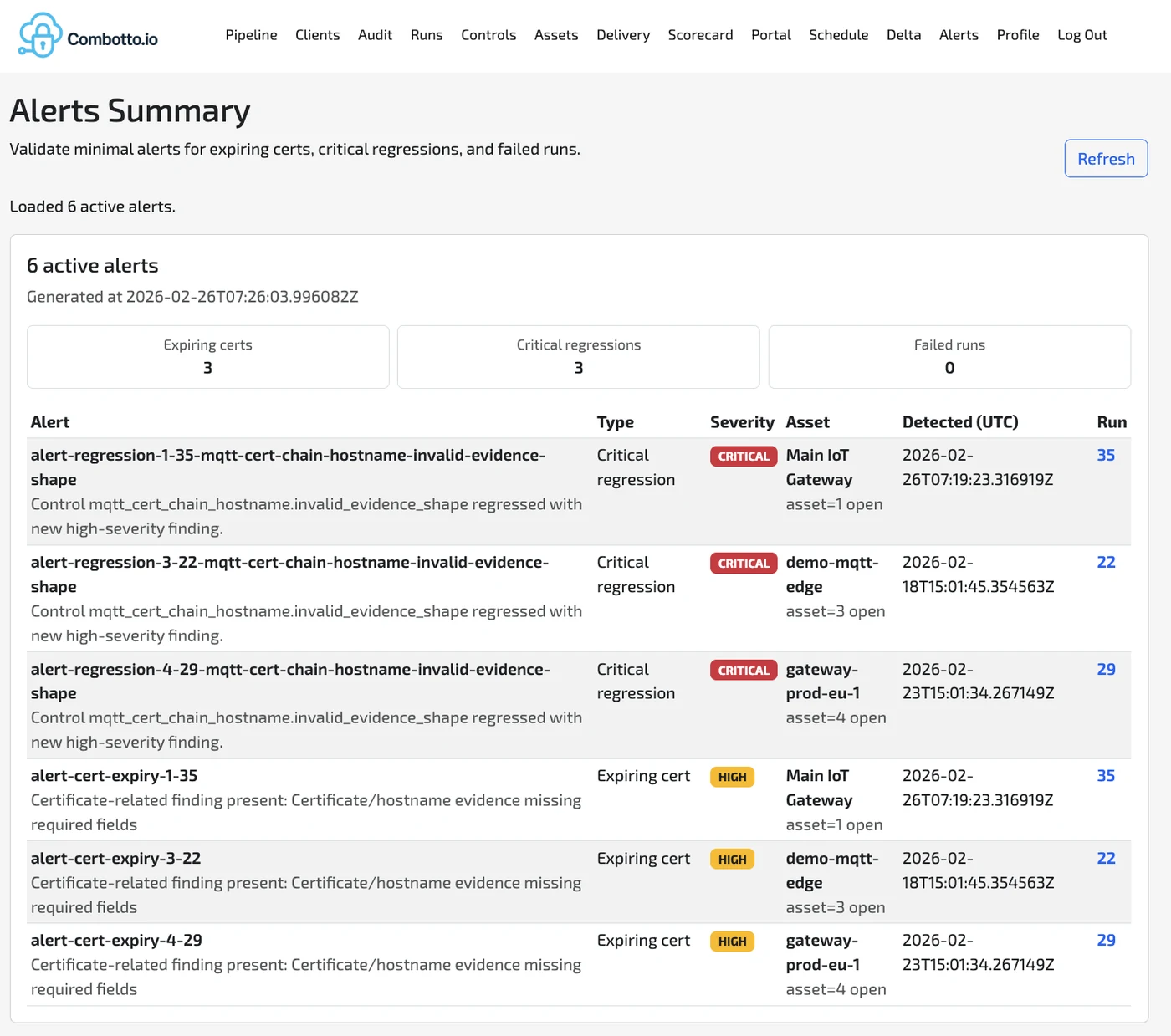
3) Alerts for expiring certs and critical regressions
Audits become much more valuable when they can turn into lightweight operational signals:
- Certificate expiry horizon / expiring cert alerts
- Critical regression alerts when something that was fixed comes back
- Visibility across multiple assets and runs
This is not “SOC monitoring.” It’s minimal, high-signal alerts connected to repeatable evidence—so teams get notified when it matters.
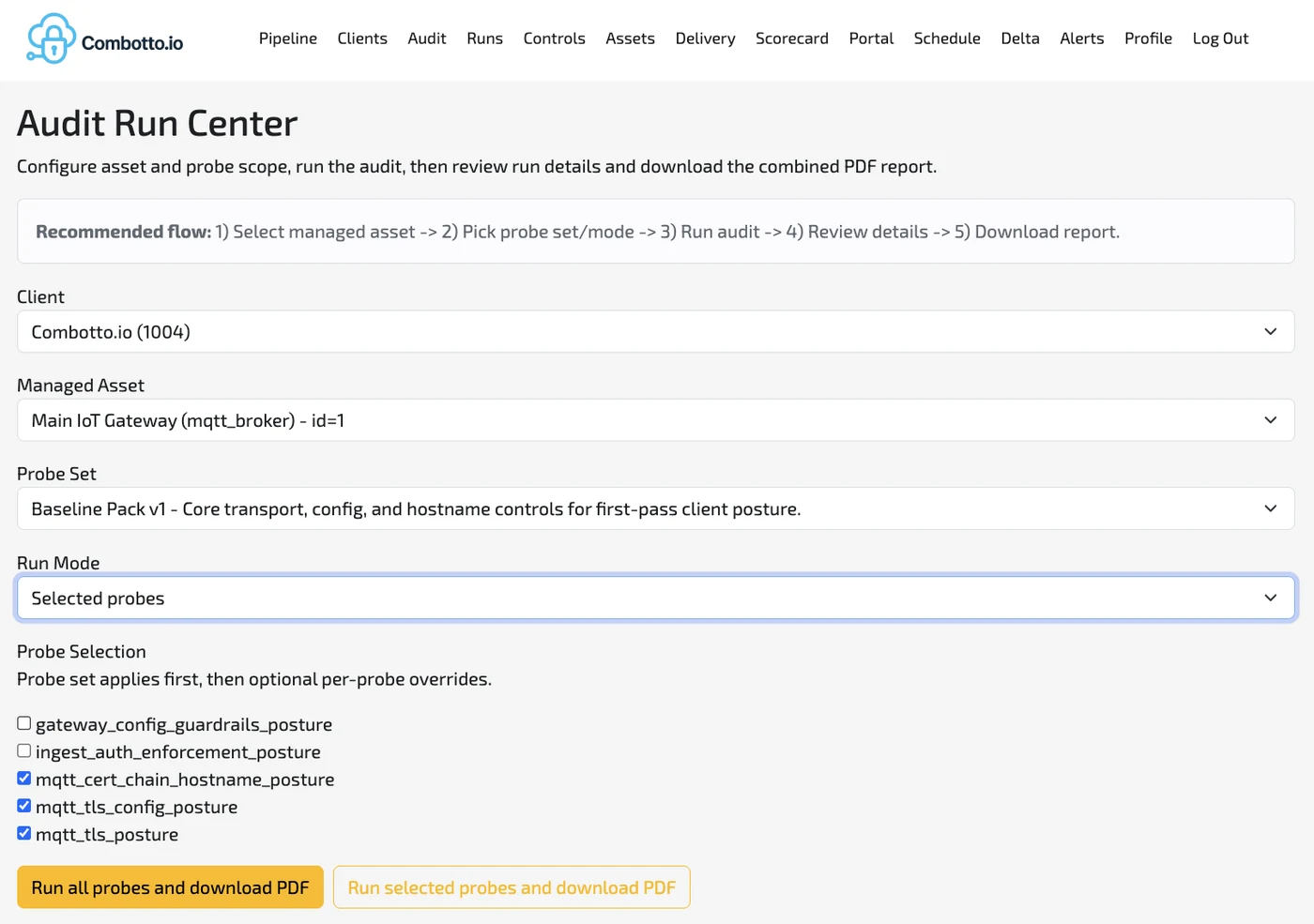
4) Audit Run Center (a repeatable workflow)
To make audits usable, running them has to be simple:
- Select client + managed asset
- Pick a probe set / mode
- Run the audit
- Review run details
- Download combined report
Probe sets let you start small and expand. For example, a baseline pack for:
- TLS handshake posture
- TLS configuration posture
- Certificate chain + hostname/SNI identity posture
Why I built it: better consulting outcomes with less ambiguity
A lot of “architecture audit” work fails in practice because the outcome is too vague:
- Findings are hard to verify
- Fixes aren’t tied to acceptance criteria
- Re-checks are inconsistent
- Leadership hears “risk” but doesn’t see proof
This engine changes the consulting loop:
- Evidence-backed findings (not opinions)
- Verification steps built into the remediation backlog
- Before/after proof via deltas
- Ongoing confidence via scheduled runs + alerts
This aligns directly with the engagement model I’m building at Combotto:
IoT Audit → Hardening Sprint → Retainer
If you want the full breakdown of scope boundaries and deliverables, it’s outlined on the IoT audit service page.
What “pilot-ready” means (and what it doesn’t)
Pilot-ready means:
- The core flow works end-to-end on real assets
- Reports + deltas + alerts are usable for delivery
- Probe sets are stable enough to baseline and iterate
- The system supports iterative hardening and re-runs
Pilot-ready does not mean:
- A massive probe library covering every control family
- A replacement for pentesting or 24/7 SOC monitoring
- A fully automated compliance “stamp” (controls mapping is optional and context-dependent)
The intention is to start with high-signal probes and expand based on real-world pilots.
Who should pilot this
This is a good fit if you have:
- An IoT gateway + broker in production (or close to it)
- A customer review, security questionnaire, or launch deadline in the next 2–8 weeks
- Known pain like TLS drift, fragile edge behavior, missing monitoring coverage, or unclear operational posture
- A desire to turn “we think it’s fine” into repeatable evidence
Pilot offer: smallest scope, highest signal
I’m opening a small number of pilots focused on 1–3 assets (typically a gateway + broker + one ingestion path).
Output is decision-ready and engineer-ready:
- Executive summary (risks + priorities + next steps)
- Technical findings across security/reliability/observability
- Evidence pack collected from real assets
- Remediation backlog with verification steps
- Optional control mapping (ISO/NIS2/CRA/GDPR) when relevant
If you want to pilot it:
- Book a 20-minute discovery call, or
- Send an email with: assets + pain + deadline
Email: tb@combotto.io
We pick the smallest scope that still gives high signal, run a baseline, and produce a backlog your team can execute immediately.
PS: If you’re curious about where I’m taking this next: more probes around durability/data loss signals, identity/access control, and observability coverage—so the engine can catch drift across the entire edge-to-cloud pipeline, not only TLS.
