1. Audit
Audit exposed the weak path.
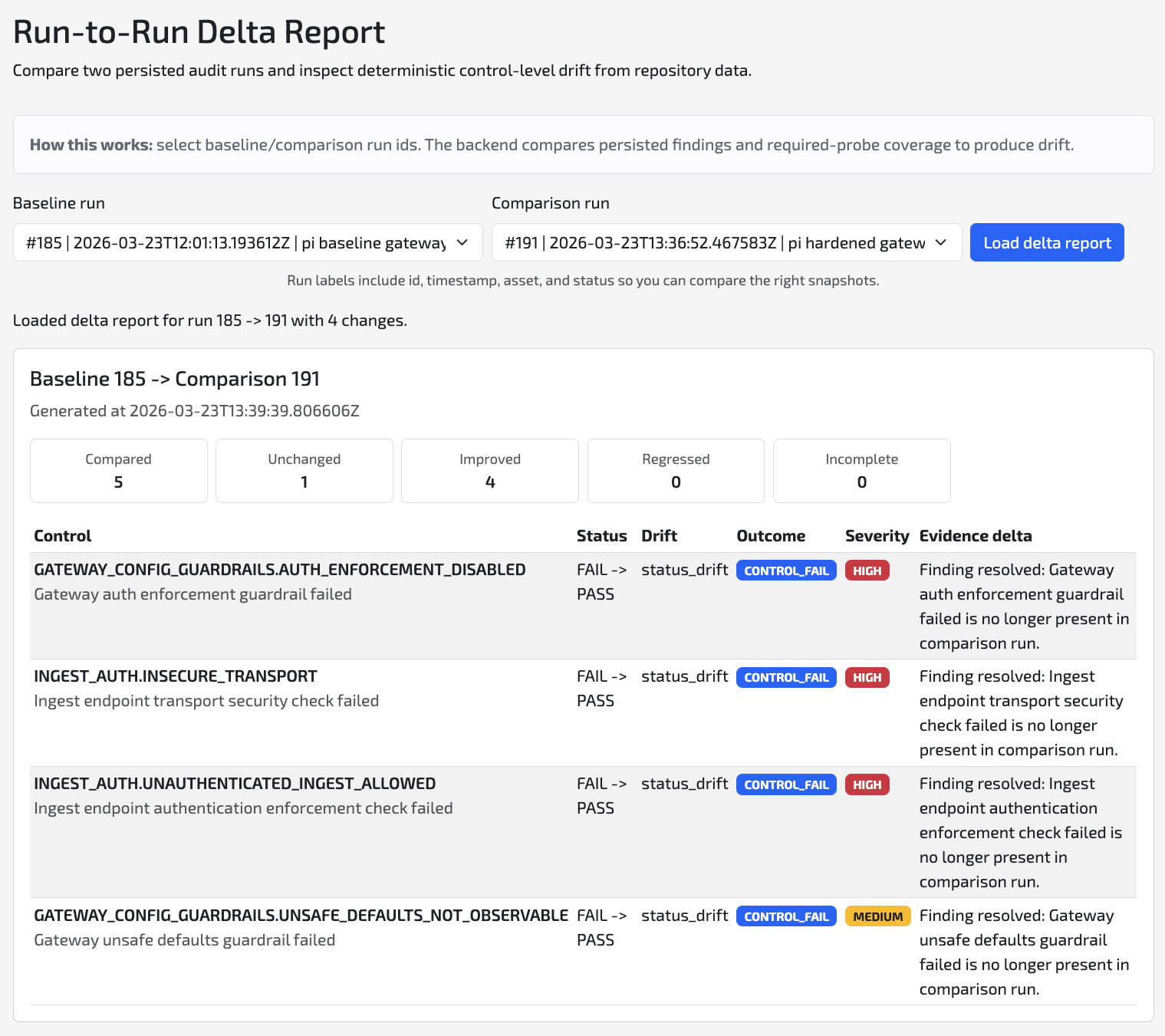
One run turned a vague gateway concern into a concrete finding set on the live telemetry path.
- Plaintext ingest and weak transport posture were still reachable
- Auth enforcement was missing at the ingest edge
- The exposed path became a prioritized backlog for the next decision
Baseline summary before hardening
Exposed posture · 4 findings