
The useful question is not whether one device can publish telemetry on a good day. The useful question is what happens when a real IoT gateway has to absorb multiple devices, a broker interruption, and recovery pressure without turning the evidence trail into noise.
That is what this field demo was built to show.
The setup used a Raspberry Pi 5 gateway, three STM32 devices, MQTT/TLS telemetry, and a write-ahead log (WAL) path that kept data durable while the upstream broker was unavailable. During the outage, backlog grew as expected. When the broker returned, the gateway drained the queue and upstream flow recovered. For teams assessing IoT gateway reliability, this is where operational truth starts to show up.
What this demo proves
- The move from one device to three is enough to expose real operational behavior, not just happy-path correctness.
- Gateway buffering and replay matter because outages do not pause field devices.
- Evidence quality depends on preserving identity, timing, and recovery behavior under pressure.
- This is the kind of field proof that makes an IoT audit credible: you can inspect what failed, what held, and what should be hardened next.

What was built in the 3-device IoT gateway demo
This demo used a small but commercially relevant topology:
- Raspberry Pi 5 running the Rust gateway
- Three STM32 field devices publishing telemetry
- MQTT/TLS transport for secured message flow
- WAL-backed buffering to persist messages during upstream disruption
- Broker interruption and return to force observable failure and recovery behavior
The point was not throughput marketing. The point was to make operational posture visible in a setup that looks much closer to field reality than a single-device lab path.

Physical setup used for the demo: Raspberry Pi 5 gateway, power, enclosure, and three STM32 devices.
What broke first when moving from 1 to 3 devices
The first thing that changes is not scale economics. It is trust in what the system is telling you.
With one device, it is easy to mistake a functioning demo for a reliable system. At three devices, you immediately care about:
- whether per-device identity stays clean end to end
- whether backlog growth is explainable during upstream interruption
- whether replay after recovery is orderly enough to trust the telemetry history
- whether a recovery event creates ambiguity about gaps, duplicates, or timing
That is the useful threshold. You do not need a fleet of thousands before reliability and evidence quality become audit questions.
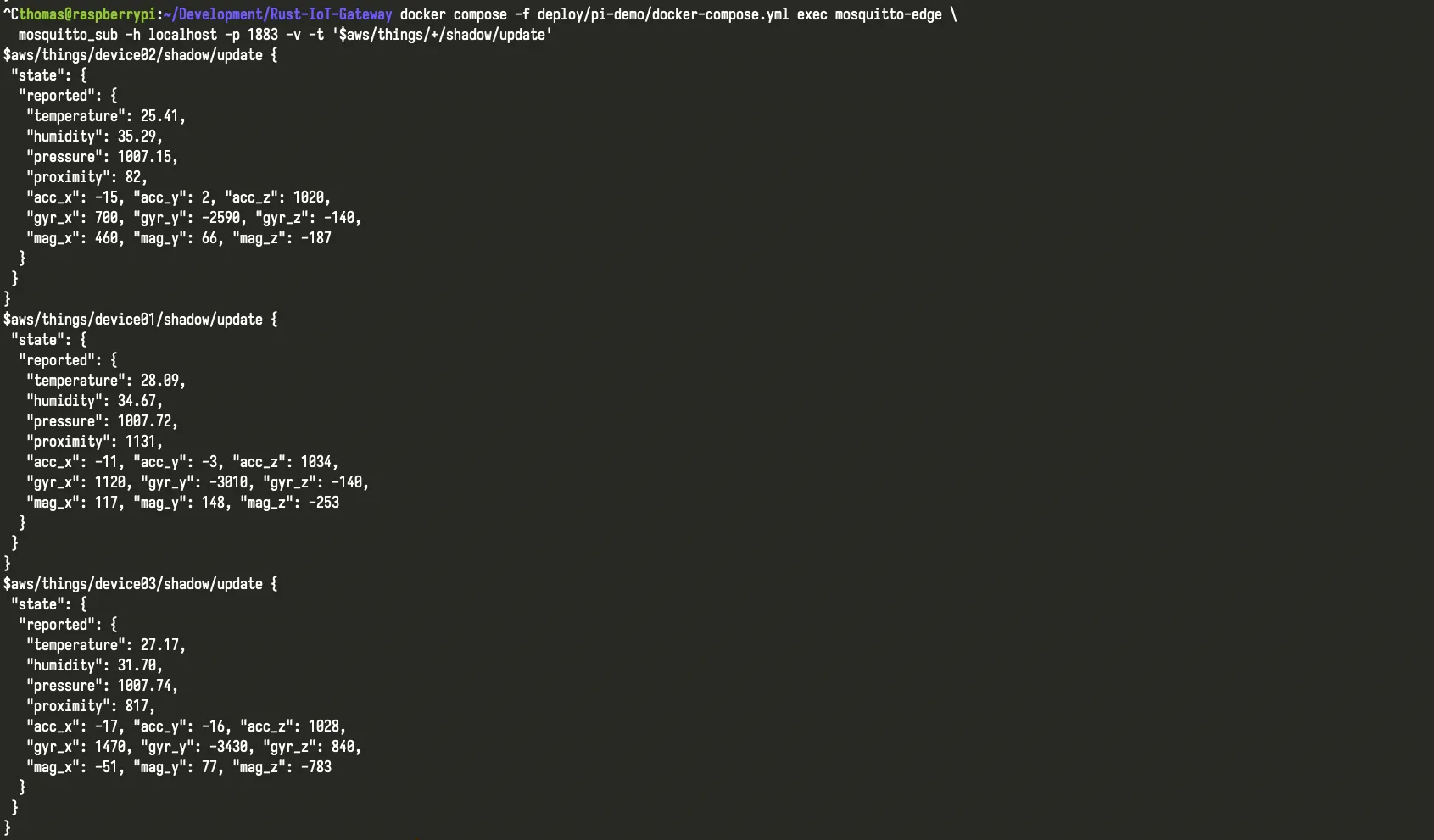
Three distinct device identities publishing at the same time. This is the point where identity hygiene and evidence traceability stop being theoretical.
How the MQTT/TLS gateway handled outage and recovery
The observed behavior matched the scenario the gateway is supposed to handle.
When the broker became unavailable, the three STM32 devices kept publishing. Instead of silently dropping the data path, the gateway continued accepting telemetry into the WAL-backed durability layer. Backlog grew during the outage, which is exactly the behavior you want to see surfaced rather than hidden.
When the broker returned, the gateway resumed upstream delivery and drained the stored backlog. That recovery path matters because it shows more than “it came back.” It shows whether the system can preserve a believable chain of evidence through interruption and return.
In practical terms, the demo demonstrated:
- durable ingest during disruption, not just best-effort forwarding
- observable backlog growth during failure instead of invisible loss
- recovery after broker return without the gateway collapsing under replay pressure
- a more credible evidence trail for any later audit or hardening decision

Structured telemetry flowing for all three devices through the gateway path, which makes per-device behavior and timing easier to inspect.
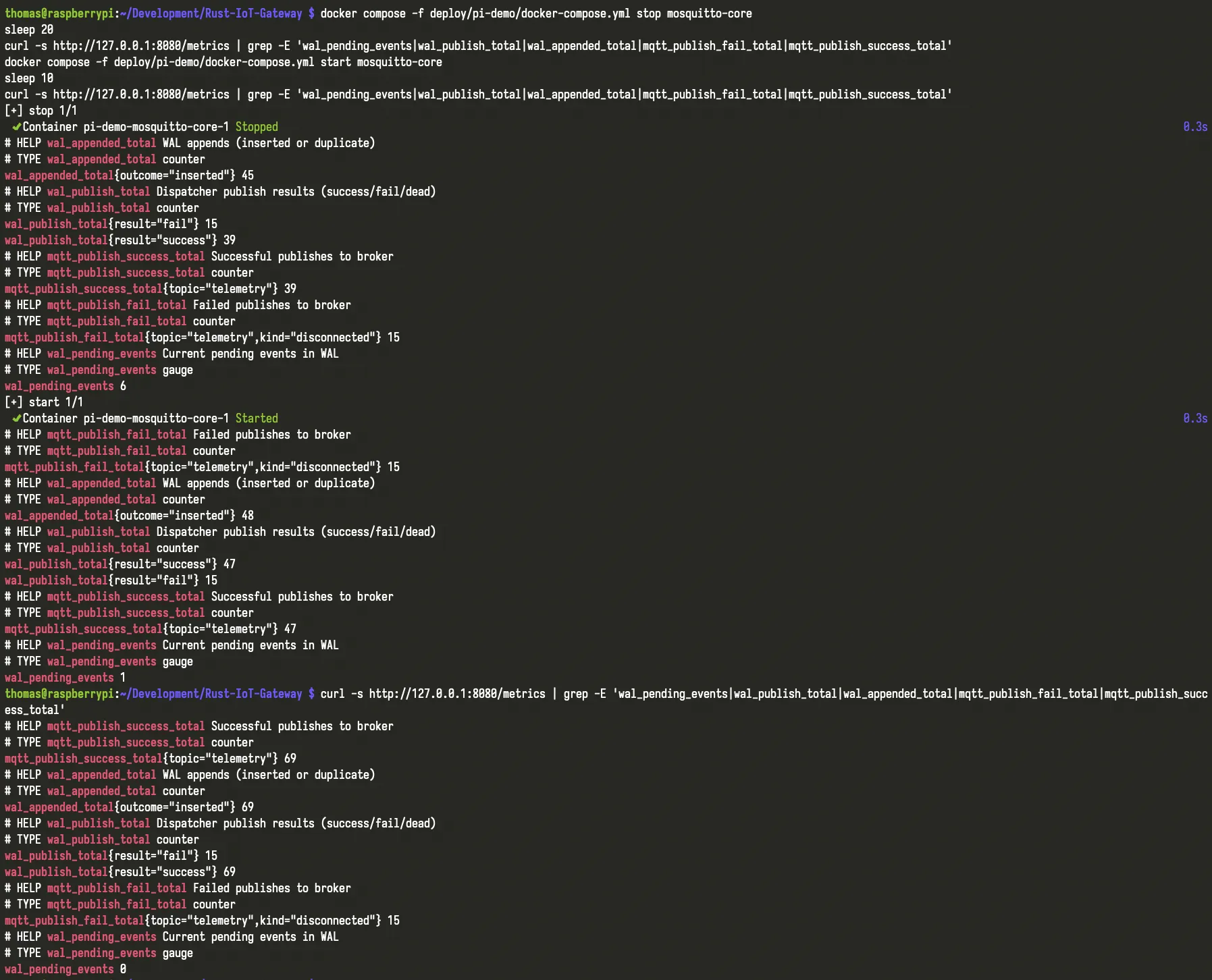
Metrics from the outage test: pending WAL events rise during broker unavailability, then drop back after recovery while publish success resumes.
Why this matters for IoT audit evidence quality
An IoT audit is only useful if the underlying system behavior can be inspected with confidence. If device identity is loose, if outages create unexplained gaps, or if recovery muddies the timeline, findings become harder to trust and harder to act on.
This is why field evidence matters before rollout.
You want to see:
- where message durability depends on one weak boundary
- whether reconnect and replay behavior stay understandable under pressure
- which parts of the path are already robust
- which parts need hardening before customer, uptime, or security pressure rises
That is also why an audit is the right first step. It turns behavior like this into a bounded review of the selected devices, broker path, buffering layer, and operational controls that matter most. From there, the next move is clearer: fix the highest-risk gaps in a Sprint, then keep posture from drifting with a lighter Retainer cadence.
What this means for teams approaching IoT rollout
If your team is moving from a proof-of-concept toward live deployment, this is the stage where hidden risk becomes expensive. Not because the architecture is catastrophic, but because small weaknesses in buffering, telemetry trust, and recovery handling compound once real deadlines and real scrutiny arrive.
The value of a field-style demo like this is that it makes those weaknesses discussable before they become an outage review, a failed customer security conversation, or a launch delay.
If you want that kind of evidence on your own path, start with the boundary already under pressure: the device group, broker path, or gateway recovery flow that leadership or engineering trusts least. That is usually the right entry point for an IoT architecture audit.
